
Googleスプレッドシートを使っていて、こんな経験はありませんか?
- メールアドレスの一覧から、ドメイン名だけを取り出したい
- 「商品コード:TS-12345」のような文字列から、数字部分だけを抽出したい
- 郵便番号「〒123-4567」の数字だけが欲しい
こんなときに大活躍するのが、REGEXEXTRACT関数です。
文字列から「特定のパターンに一致する部分だけ」を抜き出す、非常にパワフルな関数です。
ただし、正規表現という特殊な記法を使うため、慣れないうちは「思った通りに動かない」「エラーが出る…」と悩むことも。
この記事では、REGEXEXTRACT関数の基本から、よくあるつまずきポイント、実務で使える具体例まで、わかりやすく解説していきます。RACT関数の使い方をはじめ、よくあるエラーの原因とその対処法まで、具体的な使い方とともにわかりやすく解説します。
REGEXEXTRACT関数の基本構文
=REGEXEXTRACT(テキスト, 正規表現)- テキスト:抽出の対象になる文字列、または文字列を含むセル
- 正規表現:抽出したいパターンを表す文字列(例:”[0-9]+”)
よく使う正規表現の記号
| 記号 | 意味 | 例 | 説明 |
|---|---|---|---|
. | 任意の1文字 | a.c → abc などにマッチ | 「a」+何か1文字+「c」 |
+ | 1文字以上の繰り返し | [0-9]+ → 数字の連続にマッチ | 例: 12345 |
[] | 文字の集合から1文字 | [A-Z] → 大文字1文字にマッチ | 例: A, B, C など |
() | 抜き出す対象のグループ | @(.+) → @以降を抜き出す | メールアドレスのドメイン |
\ | 特殊文字を「ただの文字」に変える | \. → ドットそのもの | .は特別だからエスケープ |
よく使うパターン例
商品コードから数字だけ抜き出す
A1セルに「商品コード:TS-12345」と入力されている場合
=REGEXEXTRACT(A1, "[0-9]+")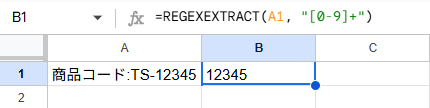
[0-9]+ は「1文字以上の数字」を意味します。
メールアドレスからドメインを抽出する
A1セルに「user@example.com」があるとき
=REGEXEXTRACT(A1, "@(.+)")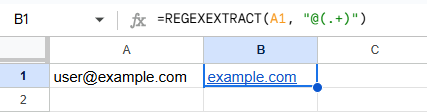
@(.+) は「@のあとに続く文字列すべて」を抽出します。() で囲んだ部分だけが取り出されるのがポイントです。
郵便番号から数字だけ取り出す
A1セルに「〒123-4567」がある場合
=REGEXEXTRACT(A1, "[0-9]{3}-[0-9]{4}")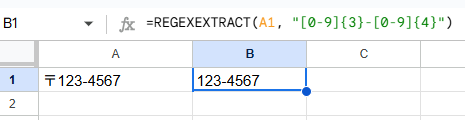
[0-9]{3} は「3桁の数字」、- はそのままハイフン、[0-9]{4} は「4桁の数字」を意味します。
よくあるエラーと対処法
#VALUE! エラー
一番多いのがこのエラーです。
この原因が起きるのは引数が文字列ではない場合です。
抽出対象や正規表現が 123 のように数字が入っている場合、以下のようなエラーになります。
エラー例:関数 REGEXEXTRACT のパラメータ 1 の値は テキスト にしてください。…
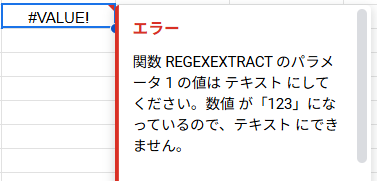
正規表現をセルに書く場合も、必ず文字列として入力しましょう。
#ERRORエラー
ダブルクォーテーションがないと数式の解析エラーになります!
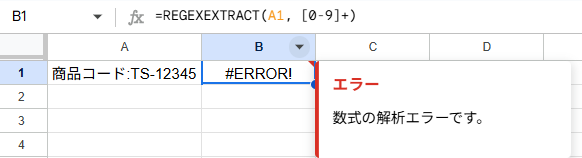
=REGEXEXTRACT(A1, [0-9]+) ← NG!
=REGEXEXTRACT(A1, "[0-9]+") ← OK!#N/A エラー
正規表現のパターンに合致する文字がなかった場合、REGEXEXTRACTは #N/A を返します。
たとえば、「商品:ABC-XYZ」の中から数字を抜き出そうとして
=REGEXEXTRACT(A1, "[0-9]+")とすると、数字が含まれていないため #N/A になります。
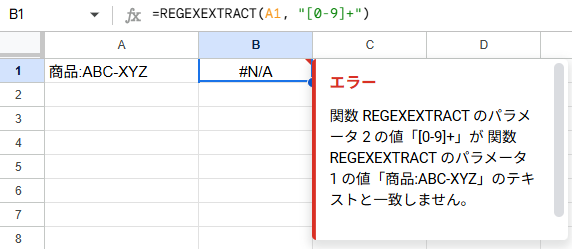
この場合は「正規表現が本当にデータに合っているか」を再確認してみてください。
抽出結果が変になる理由と対処法
ドット(.)や括弧(())は特別な意味がある
たとえば、ファイル名「ver2.0」から「.0」だけ抜き出したいとき
=REGEXEXTRACT(A1, ".0") ← これはNG!
=REGEXEXTRACT(A1, "\.0") ← 正しくはこう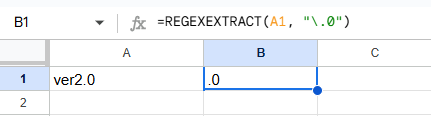
. は「任意の1文字」という意味なので、そのまま使うと意図しない結果になります。
文字として扱いたい場合は \. のようにバックスラッシュでエスケープしましょう。
「長く取りすぎる」問題は「非貪欲マッチ」で回避
REGEXEXTRACTは、マッチできる範囲が複数あると、できるだけ長く一致する部分を優先します(これを「貪欲マッチ」といいます)。
たとえば、A1セルに「No:123-456-789」があるとき、以下の式は…
=REGEXEXTRACT(A1, "No:(.*)-")と書くと、「123」という結果にならず「123-456」となる。

解決策:* を *? に変えて「最短一致」に
=REGEXEXTRACT(A1, "No:(.*?)-")このようにすれば、最初の - までで止まり、「123」が抜き出されます。

まとめ|REGEXEXTRACTで文字列処理を自動化しよう
REGEXEXTRACT関数は、パターンに一致した文字列だけを自動で抜き出せる非常に便利な関数です。
ただし、正規表現のルールやスプレッドシートの仕様に少し癖があるため、次のポイントを押さえて使うと安心です。
- 正規表現は必ず文字列(” “で囲む or 文字列セルを参照)で書く
- エラーが出たら、参照セルが空・数値になっていないか確認
- ドットや括弧は
\.\(などでエスケープする - 取り出す範囲が広すぎるときは
*?や+?で最短一致を試す
データ入力・整理の作業がぐっとラクになりますよ。
ちょっとずつ慣れて、正規表現を味方につけていきましょう!










